Activities
·····
2026-07
Google Cloud RoleUp
Google Cloud の IAM ロール・権限を探索・比較できるサイト
`make` is missing from `:slim` images (575.0.0-slim and later)
### Summary `make` is missing from the `:slim` tag starting at `575.0.0-slim` (`2026-06-30` build). Both [README.md](https://github.com/GoogleCloudPlatform/cloud-sdk-docker/blob/master/README.md?plai...
2026-05
技術選定の舞台裏 第9回
技術評論社の雑誌 Software Design に 8 ページ寄稿しました
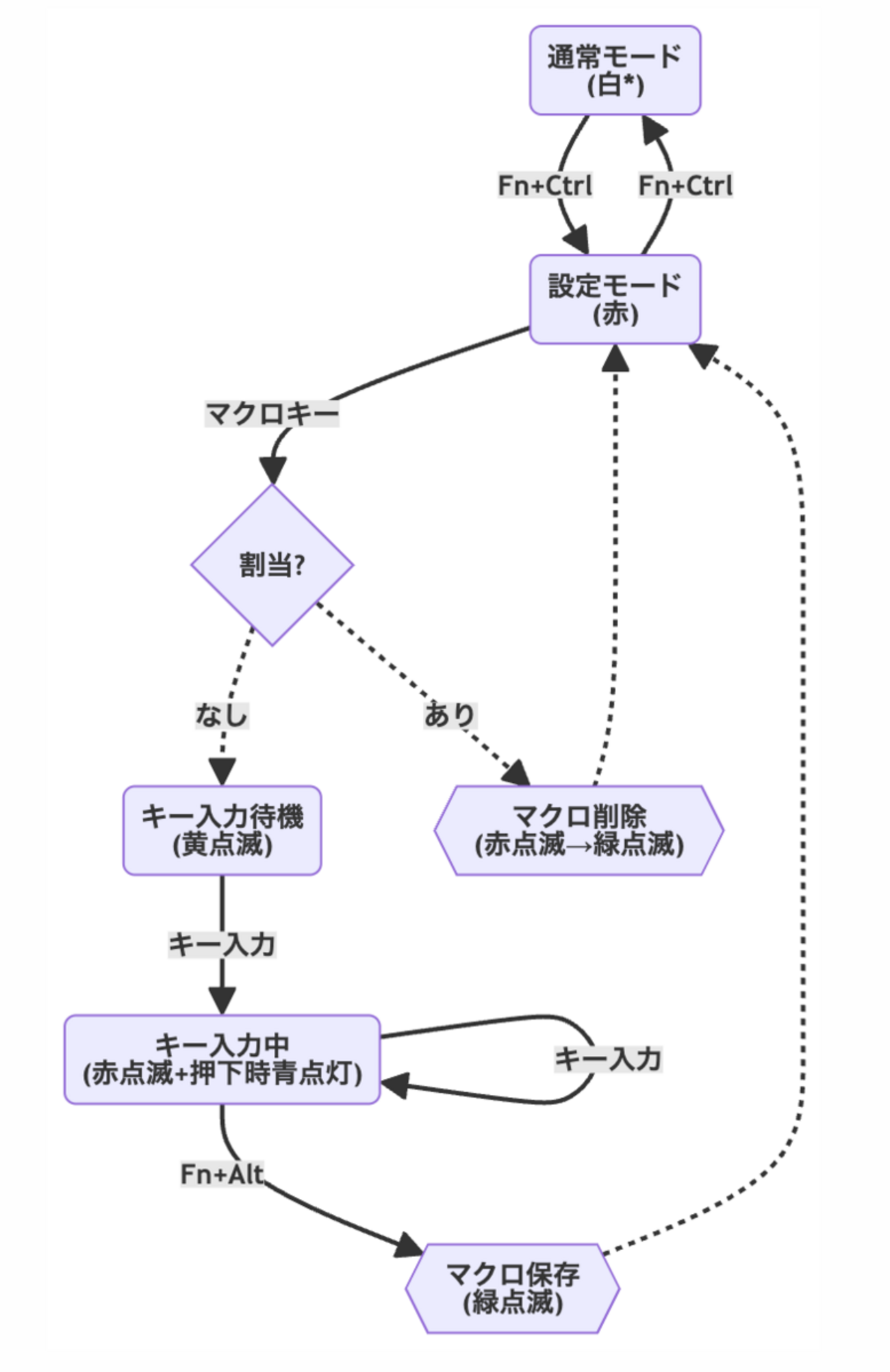
分割キーボード FILCO Majestouch Xacro M10SP の話
2年前に分割キーボードが欲しくなって購入、それ以来愛用している。 値段も高すぎず、入手性もよく、内側に1列ずつホットキーがある意欲的なレイアウトも良い。 商品画像 ホットキー 自分は B を右手で打つことが多く(流れで左でも)、分割キーボードだと右手で打てず矯正を余儀なくされるが、間のホットキーに割り当てることで両手で B が打てる。 他には右親指で Esc を押したり、音声入力や特定アプリケーシ...
2026-04
2026-03
ファインチューニングせずメインコンペを解く方法 (技能賞 解法発表)
ファインチューニングせずメインコンペを解く方法

2025 大規模言語モデル 応用 優秀賞
最終課題の LLM トレーニングコンペにおいて メインコンペ3位 / アドバンスドコンペ2位 / 技能賞 を頂き、修了イベントで解法発表を行いました。