Blog Entries
ぽ靴な缶
AI で再注目された技術やツールたち
これは はてなエンジニア Advent Calendar 2025 2 日目の記事です。 年の瀬なので振り返りたくなる季節ですね。 今日はそんな「以前から存在していたけど AI によって新しい価値を見出された技術やツールを語ろう」のコーナーです。 いくぞ!! Server-Sent Events (SSE) まず出世頭として思いつくのは Server-Sent Events でしょう。 Server-sent events - Web API | MDN 今やチャット AI のレスポンスはほとんど SSE で送られて来ています。 SSE は HTTP レスポンスとして、以下のような空行区切りの data: から始まるテキストデータを送る方法です。クライアントサイドではレスポンスの送信終了を待たずに受信したデータを逐次使うことで段階的な表示を行います。 data: Yo data: 俺の名前は data: ぽくつなだぜ # 実際には JSON など構造化したデータを送る SSE 自体はずっと前からあって、2004 年の WHATWG の提案に起源があるようですね1。 自分が SSE を認識したのは、WebSocket & socket.io が流行った後ぐらいだったと思います。 Lingr というチャットサービスは HTTP ベースなんだけど Comet という方法で通信していて...みたいな。流行ったから WebSocket 使ってるだけで、その用途なら SSE のほうが簡単なのでは? みたいな実装も見かけたり。 ChatGPT を初めて触った頃、これどうやって作ってるんだろ? と Developer Tool で眺めて Content-Type: text/event-stream を見た時は、なるほど!! と思ったものです。 EventSource が GET しか使えないのもあり、当時はチャットルーム的なエンドポイントに GET で接続して更新を降らせるイメージでしたが、最近のチャット AI ではユーザ入力の POST に対して AI 生成レスポンスを SSE で返す形なのがちょっと新しい感じですね。昔からやってる人は居たとは思うけども。 Pandoc での Markdown 化 Pandoc は様々なドキュメントを変換できるツール。 AI を使って論文やスライド、電子書籍を読みたい。今やチャット AI 側の対応が充実して直接渡せるようになってきているわけですが、2023 年頃は自前でテキストデータに変換したりベクトルインデックス作ったりしていたわけです。今でもフォーマットによってはやる必要がある。 EPUB を Unstructured を使って変換しようとしたところ依存に含まれている Pandoc と再会。 お前とこんなところで会うとは... 昔 Markdown と Redmine の Textile を変換してくれたよね。はてな記法も2変換しちゃったりね、懐かしいじゃん。ああうん、また今度飯でも行こうよ、みたいな。 Pandoc は珍しい Haskell 製のツールとしても知られていますが、リリースは 2006 年なんですね。フォーマット変換が普遍的なタスクであることを考えてもなかなかすごい。 Google Trends - Pandoc の伸び テキスト化というトピックでは、最近の OCR も勢いがありますね。 DeepSeek-OCR が話題になりましたが olmOCR や Mistral OCR も今年出たモデル。LLM/VLM の発展によって色んなモデルが公開されました。日本語では YomiToku が出たり。ちょうどこの記事も話題になっていました。 tech.layerx.co.jp Markdown 自体も AI で再注目されたフォーマットといえるかもしれません。少し前まではウェブエンジニア向けテキストフォーマットという雰囲気だったけど、今や AI と構造化テキストをやり取りする際の標準的な選択肢になっている感じがありますね。 Marp でスライドを作る Markdown つながりで Marp を久々に使いました。 Marp は Markdown でスライドを作るツール。2016 年頃に話題になって流行りました3。今年勉強会の資料をコーディングエージェントを使いつつ Marp で作ったら内容より「懐かしっ」という反応を頂いて、まあ確かにそうだなと。 最近、Markdown から Google スライドを生成するツール k1LoW/deck も話題になりましたね。LLM の支援を受けられるテキストベースのツールが再注目されている流れがあります。 Markdown から何かを生成する方面では、Mermaid で描かれた図を見る頻度も増えた気がします。AI に描かせるだけでなく、テキストで関係性を表現するために Mermaid 記法を使って AI に入力する事例も見ますね。 アクセシビリティツリー 「情報をどうテキスト化して入力するか」という文脈では、Playwright MCP がブラウザ操作にアクセシビリティツリーを使って成功していたのが印象的でした。 この記事のアクセシビリティツリー(Playwright の ariaSnapshot)を見てみるとこんな感じ - generic [active] [ref=e1]: - iframe [ref=e3]: - generic [ref=f24e3]: # ... - generic [ref=e21]: - generic [ref=e22]: - generic [ref=e24]: - article [ref=e25]: - generic [ref=e26]: - generic [ref=e27]: - link "2025-12-02" [ref=e29] [cursor=pointer]: - /url: https://blog.pokutuna.com/archive/2025/12/02 - time [ref=e30]: 2025-12-02 - heading "AI で再注目された技術やツールたち" [level=1] [ref=e31]: - link "AI で再注目された技術やツールたち" [ref=e32] [cursor=pointer]: - /url: https://blog.pokutuna.com/entry/ai-rediscovered-tech-and-tools - generic [ref=e33]: - paragraph [ref=e34]: - text: これは - link "はてなエンジニア Advent Calendar 2025" [ref=e35] [cursor=pointer]: - /url: https://qiita.com/advent-calendar/2025/hatena - text: 2 日目の記事です。 - paragraph [ref=e36]: - text: 年の瀬なので振り返りたくなる季節ですね。 - text: 今年も AI の話題が非常に多く、コーディングエージェントの普及を始めいろんな変化がありました。新しいモデル、高まる精度、飛び交うビッグマネー、跳ね回る驚き達。そういう景気の良い話はさておき、既存の技術が新しい文脈で再注目されたり、思わぬ用途で広く使われるようになったりすることも起きています。 - paragraph [ref=e37]: 今日はそんな「以前から存在していたけど AI によって新しい価値を見出された技術やツールを語ろう」のコーナーです。 生の HTML は巨大でノイズも多く AI に渡すのは厳しいです。そこで Playwright のテストにおいて、ページ構造の比較に使われていた ariaSnapshot が、ページ構造を伝える手段に転用されています。 従来 Playwright や React Testing Library は、テストを書く際に id や class 属性での参照ではなく、role や label での参照を推奨していて、ユーザがアプリケーションを使う時と近い形でテストを書くように促していて、それが結果的に AI にとっても扱いやすいシリアライズ形式になった、というのが面白いですね。 ブラウザ操作の先駆け browser-use によるインタラクティブ要素のハイライト & 可視化 音声入力 再注目? というと違う気もするけど、自分は今年からだいぶ音声入力を使うようになりました。 コーディングエージェント以前は、補完を活用して書きまくっていたわけだけど、今は AI に指示をする際に主語述語目的語の揃った文章を書くことが増えてきた。複数の入力欄を行ったり来たりしつつ、都度文章を整えるのは地味に手間で、音声入力できるとなかなか便利です。 2022 に OpenAI が Whisper を公開し、その高い精度に驚かされたのも昔の話。ここ1年ぐらいで Whisper を使って文字入力するデスクトップアプリがいくつか出ました。今年の3月ぐらいに Superwhisper や Aqua Voice が話題になって流行ったかな? 自分は VoiceInk を使っています。OSS なのでちょっと改造して使っている、こういう選択肢があるのはいいですね。 その他 自分は使っていないけど Obsidian がドキュメントツールとして再注目されたり、RAG の文脈でナレッジグラフを作って retrieval しようという GraphRAG が話題になって久々に Neo4j の話を聞いたり。 コーディングエージェントを走らせるため sandbox 技術にも注目が集まりました。自分は最近まで知らなかったけど、2016 年ごろの Sierra 頃から非推奨の sandbox-exec を、Codex、Claude Code、Gemini CLI、Cursor 全員が開き直って使ってるというのもウケますね。 まとめ 以上、AI で再注目された技術やツールを紹介しました。 Twitter で教えてください。 これは はてなエンジニア Advent Calendar 2025 2 日目の記事でした。 id:mizdra さんの 普段使いできる保護レイヤー「restricted shell」の紹介 - mizdra's blog でした。 id:todays_mitsui さんの予定です。お楽しみに!! { entries.forEach(entry => { if (entry.isIntersecting) { typeText(); } else { clearTimeout(animationId); } }); }); observer.observe(element); https://en.wikipedia.org/wiki/Server-sent_events↩ https://motemen.hatenablog.com/entry/2017/05/pandoc-hatena↩ https://b.hatena.ne.jp/entry/s/yhatt.github.io/marp/↩
ぽ靴な缶
松尾研LLM講座申し込み締切もうすぐ!! & 2024 年講座の思い出
日記AI大規模言語モデル講座 応用編 2025 Autumn - 東京大学松尾・岩澤研究室(松尾研)- Matsuo Lab 2025/11/19(水) AM10:00 まで!!! 社会人枠もあります。自分は前年に参加してとても良かったのでおすすめしています。 各社の LLM API を雰囲気で利用していて、理解が足りてないな、もどかしいなと感じて応募したのですが、そういった Web エンジニアの方々は多くいるのではないでしょうか。 前年の講義スライドは公開されている。 LLM 大規模言語モデル講座2024講義スライド - 東京大学松尾・岩澤研究室(松尾研)- Matsuo Lab あ、応募に名刺が要る気がするな、締切2日前に言われても準備できないかもな、まあいいか 2024 年講義の最終課題コンペで優秀賞を頂きました 自分は去年の講義に参加させて頂いて、一般8位、コントリビューション3位の優秀賞を頂きました。この自慢をする機会を逸し続けていた。 枠が NN になってるのが良い 講義の内容も良かったのだが、特に自分で手を動かす機会としてコンペがあったのは良かったです。 コンペの内容は 事前学習済みモデルを訓練し ELYZA-tasks-100 の改変版に対し高いスコアを出す LLM を開発する 2024年9月以降の日本のテレビ番組内容で各タスクのトピックを置き換えて若干難易度を上げたもの 制約として、 利用可能な事前学習済みモデルは LLM-jp-3 または Gemma2 (自分で事前学習しても良い) L4 GPU 1 枚の環境で 1 時間以内に 100 問に回答 モデルが公開可能であること(データとモデルのライセンス遵守) 予選は自動評価、決勝は参加者による評価 というものでした。 自分は、 gemma-2-9b をベースに継続事前学習 → SFT → DPO したものをメインに使う Gemma がことわざ・慣用句などの日本語文化問題に弱かったので、llm-jp-3-13b を SFT したものをサブモデルに用意 という構成で勝負。 問題文からルーティングする分類器を作るつもりだったけど、これ問題文のバリエーション無いなと思ったので正規表現で済ませたり、締め切り直前に苦手な問題の学習データを自分で作ってみたり pokutuna/tasks-ime-and-kakko-jp、人間の目視評価ってことは TeX 記法や Markdown が丸出しなのは見栄え悪いよな...と思って置換してみたり、意味あることもないことも色々試す機会になって楽しかったです。 最初は GPU 代を払うことにケチケチしていたけど、 社会人にあって学生にないもの、それは金... GPU が使える...安すぎる... RunPod に円を注入することを覚えました。 早く来すぎた 個人的に衝撃を受けたのが表彰式 & 懇親会で、めちゃくちゃ色んな人が来ていたことですね。 高校生から60代、寝たきりの方、仕事で LLM 訓練している人、研究者、医師まで居て、属性が多様すぎる。 たった 1 年前の話なのに AI の話題が色々ありすぎてもう懐かしい。 これは当時のな〜〜んにもわからないところからスタートした際のメモ書き、下から上に書いてある。 2024/11 LLM チューニング日記 - pokutuna ちょうど Twitter で盛り上がっている話題として 松尾研発スタートアップ - 東京大学松尾・岩澤研究室(松尾研)- Matsuo Lab 胡散臭いと思われる理由の1つとして、講座を受講しただけで「松尾研卒です!!」みたいなこと言ってる例はたまにあるよな... 毎年 3000-4000 人が参加していてそういうこともある、自分はその間口の広さによって良い経験をさせてもらえたので、不届き者をシバきつつ今の感じで続いてほしいなと思います。

ぽ靴な缶
開いているブラウザの内容を読める MCP サーバー
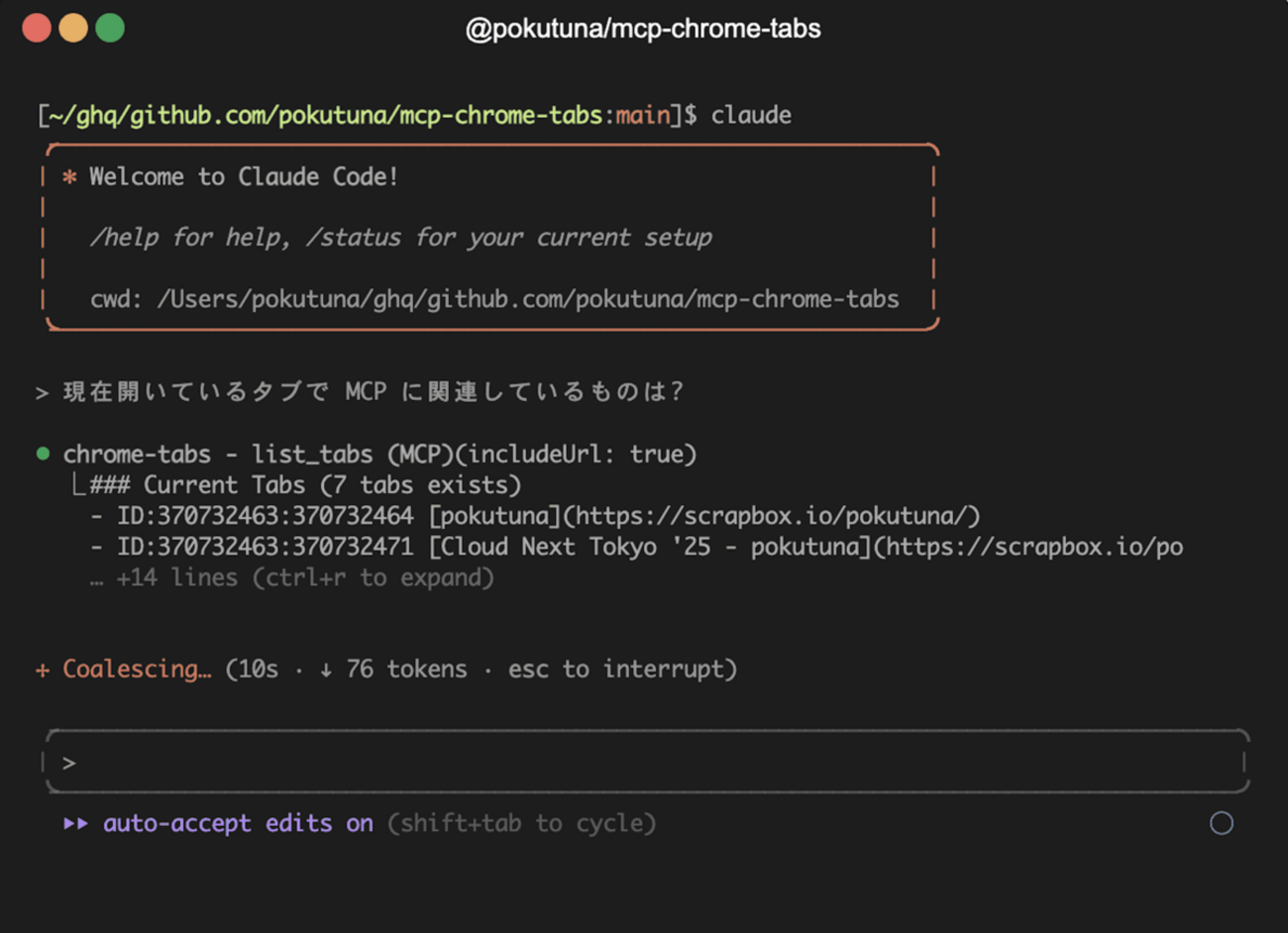
AIツール作ったを作りました @pokutuna/mcp-chrome-tabs デモ AppleScript を使っている都合上 macOS でのみ動きます。 なぜ作ったか 既に LLM にブラウザを操作させる技術は色々ある。browser-use、playwright-mcp、mcp-chrome などなど。 これらの Tool, MCP は便利だけど、様々なツールが入っていてコンテキストへの圧迫が大きく、Chrome の debugging port を開けたり、普段のユーザディレクトリは使えなかったり、ブリッジとなるブラウザ拡張入れたりなど、まあまあめんどく、普段遣いしたいかというと否である。なのでタスクに応じて MCP サーバーのセットを切り替えて暮らしている。 ただ今開いているページを LLM に読ませたい 普段はブラウザ操作をしたいわけではなく、今見ているページを LLM に読ませたいことがほとんどだなと気づいた。 いまや大抵の AI アプリケーションは URL を取得して読んでくれるし、検索エンジンを使えたり便利になっているものの、様々な煩わしさがある。 URL を貼っても読んでくれず「fetch して」と追加で指示 取得し始めるものの robots.txt に阻まれる "代わりに別のページを検索します" やめてくれ〜 検索したら「これは別の話だな...」「古いの参照してるな...」と実行を停める 認証情報がなく見られない、与えるのもひと手間 長大なページを読んで Prompt too long エラーで死ぬ ただ俺が今見てるページ読んでくれ!! という気持ちで作ったのが @pokutuna/mcp-chrome-tabs です。 機能・特徴 Apple Script 経由でタブのコンテンツを取得する 追加の HTTP リクエスト送らず、ページの内容をそのまま参照 本文部分を取得し Markdown に変換 @mozilla/readability の代替を目指す defuddle を使う ツール 3 つのみ、説明も出力も短めで普段遣いできるように list_tabs: 現在開いているタブの一覧を取得する read_tab_content: 指定したタブの本文部分を Markdown で取得する open_in_new_tab: AI 側からユーザのブラウザで URL を開けるように 実験的に MCP Resources に対応 Claude Code の @ 補完にタブの候補が出ます 単純な MCP サーバーで似たものもいくつかあるけど、意外と満足行くものがなく1作ることにしました。 名前に chrome と入れてしまったけどオプションを指定することで Safari でも動く。 使い方 以下のような感じで MCP サーバーとして追加します: { "mcpServers": { "chrome-tabs": { "command": "npx", "args": ["-y", "@pokutuna/mcp-chrome-tabs@latest"] } } } Claude Code の場合は以下のコマンドで: $ claude mcp add -s user chrome-tabs -- npx -y @pokutuna/mcp-chrome-tabs@latest その後、Chrome のメニューから 表示 > 開発 / 管理 > Apple Events からのJavaScript を許可 AppleScript 経由からの Chrome の操作を許可してください。2 実際の使用例 作ってからほぼ毎日使っています。こんな感じで活用中。 議事録開きながら「決定事項を箇条書きにして」 コーディングエージェントが新しすぎて LLM 側に情報がないような作業するときに、公式ドキュメントやリファレンスを開いておいて「タブ一覧から関連する内容を確認してから作業して」 リポジトリにない設計ドキュメントを開いておいて 「現在のタブの内容から重要なものを CLAUDE.md に反映して」 手で丁寧に渡すなどの代替手段でできることではありますが、いきなり指示して読めるのが便利。 defuddle の本文抽出都合でうまく取れないケースもあり改善したいものの、まあ大抵はうまくいきます。本文テキストを取り出すものなので、具体的には GitHub のコードのページなんかはうまくいかないけど、URL を確認してから gh を使ってくれたり / 使うよう促したり。 MCP Resources プロトコルに対応 Tools だけでなく MCP の Resources プロトコルにも対応してみました。 Claude Code では @file で特定のファイルを参照させることができるけど、その補完候補に Resource を登場させることができます。@cur で tab://current の参照を補完させたり、@{ページタイトルやホスト名の一部} など引っかかるワードで補完候補から選べます @ で補完候補に出て選べる タブ集合の差分を検出してリソースリストの再取得を促す listChanged notification を送る実装もしていますが、まだ Claude Code 側が対応しておらず起動時のタブリストから更新されない。まあそのうち対応されるでしょう... まとめ 使ってみてね おまけ情報: playwright-mcp 公式のブリッジ拡張が来そう リポジトリを見ると見つかる。まだ動きはするけど PoC かな? 再接続ができなかったり親切さゼロだったり。 playwright-chrome-extension - pokutuna Chrome コネクタも似たような仕組みではあるものの、実装がいまいちで本文部分の切り出しがなかったり。↩ Chrome が制限厳しくしたのに横穴開けている感はあるので注意は必要↩
ぽ靴な缶
書いてない記事2025夏
日記生活ブログに書きたいと思いつつ書いてない話の供養です Google Open Source Peer Bonus Award 頂きました Dataform へのコントリビュートで貰った、2023 年末の話... Majestouch Xacro M10SP 良い 自作に手を出したくないが分割キーボードは欲しい、このマクロキーの配置は良くめっちゃ使ってる Google Processional Cloud Security Engineer を取得した 本来は資格延長のためのバウチャーぽかったけど新しいことを知りたかったので、正直使わない知識(US の法規制とか)も多かったけど面白かった はてなインターン 2024 で AI に関する講義をした 時流にあわせて AI の話をする、歴史っぽい話から、ベンチマーク鵜呑みにするなよという話 東京大学松尾・岩澤研「大規模言語モデル2024」の公開講義を受講した 最終課題は受講生同士でバトルするコンペ、3000人?中、一般8位&コントリビューション3位になった、これはちゃんと書きたい Modern App Summit '25 基調講演で話した Google Cloud イベントの基調講演中の 10 分枠で発表した、短いし楽かと思いきや自分のトークを聞きに来てない聴衆に話すのは難しい、ふわっとした話になって反省 もっと細かく書きたいとは思っています。思ってはいる。
ぽ靴な缶
Emacs 時代の愛用テーマを VSCode テーマにした
VSCode作ったAIOSS活動AI と一緒に作った。このようなテーマ。 pokutuna.vscode-gnome2like-theme marketplace.visualstudio.com このテーマは Emacs の color-theme.el に含まれる color-theme-gnome2 を起源とした配色です。 故郷 学生の頃、2008 年あたりにから Emacs を使い始め、仕事でも長く Emacs を使っていたけど、TypeScript の書く体験の良さから徐々に VSCode の比率が上がっていったり Live Share でペアプロをする必要が出たりして、今では VSCode がメインエディタになってしまった。今ではほぼ Emacs を起動していないが、Emacs を故郷《ふるさと》にように思っている。 当時 Emacs では color-theme.el の color-theme-gnome2 を愛用していた。 emacsmirror/color-theme-modern より引用 この Dark でも Light でもない緑ベースのテーマの中で、あらゆるプログラミング活動を行っていたよな。 この配色が好きで VSCode に持っていきたいと思っていたが、指定する色数が多く腰が重かった。 Emacs に比べると VSCode テーマで指定しなきゃいけない色数はめちゃくちゃ多く、過去のメモによると 2019 年ごろにもトライして飽きている。せっかくコーディングエージェントが流行っているので改めてやってみようと思い立って実装した。 Roo Code と sonnet 3.7 と gemini-2.0-pro-exp (書いてる時は 2.5 出てなかった) に指示を出すと、あれよあれよとできていき、完成度 70% ぐらいまですぐ行けた。 今や VSCode がメインエディタとなって久しいが、Emacs 時代にずーーっと愛用していた color-theme.el の gnome2 テーマを Roo Code と一緒に VSCode に再現している、整っていくにつれ懐かしさで泣きそう pic.twitter.com/BSRclQTgRb — pokutuna (@pokutuna) 2025年3月2日 とはいえここからが長く、UI 上の指定が足りないところや syntax highlight のトークンごとの指定、一貫性に欠ける部分を修正していく必要があった。 仕事しながら2週間ぐらい使って不満があらかた消えたので、公開することにした。 こちらからどうぞ。 GNOME2-like Theme - Visual Studio Marketplace 黒すぎず白すぎず、目に優しいユニークで好ましいテーマですね。 作業中に使っている都合で Cline/Roo でもそれなりの見た目です。 badge.background や badge.foreground を token 数とか出てるパネルに使うのは違うんじゃないかと思うが、バッジとしてもパネルとしても違和感ない色に着地させる。 RooCode 当初はベタ移植を考えていて color-theme.el 全部 VSCode に持ってきたら面白いんじゃないかと考えたけど、VSCode の UI に合わせて色数をだいぶ補う必要があり、思い入れのないテーマの色を変に AI で補って完成させても誰も嬉しくないだろなぁとやめた。自分が愛用していた gnome2 のみを、色を補ったりアレンジした点もあるので -like suffix をつけ公開することにした。これはこれでウィンドウマネージャの GNOME 側に失礼な気もしなくはないが、そこは color-theme.el 時代からそうだということで。 半ばこの類の緑色がアイデンティティ化していて、このブログのテーマもそうだし、キャラエディットできる系だと緑を入れちゃうんだよな。覚えやすい ■#008080 を使いがち。 AC6 ノウハウ VSCode カラーテーマ JSON の色部分を消して、テンプレートとして埋めてくださいと指示する Emacs の色名は hex とのマッピングを csv で与えるとよい pokutuna/vscode-gnome2like-theme@main - resources/colornames.csv color-theme.el 巨大なので必要な部分だけ切って与える、GPL なので派生著作物も GPL にする テーマ = VSCode 拡張の開発は Debugger で行うのだが、テーマ JSON そのままは拡張だと思ってくれないので以下を .vscode/launch.json に置くとよい { "version": "0.2.0", "configurations": [ { "name": "Extension", "type": "extensionHost", "request": "launch", "args": [ "--extensionDevelopmentPath=${workspaceFolder}" ] } ] } UI から色の設定名を特定するには Theme Color | Visual Studio Code Extension API をじっくり見る VSCode 中の Developer Tools を開いて var() や Computed から辿る シンタックスハイライトにおいて特定の言語に依存したトークンの記述は最小限にしたいのでそう指示する & ある程度できたら置き換えさせる ストア公開用のスクショを取るためのスクリプトも AI に書いてもらった ユーザディレクトリ切り替えていい感じにできない? と頼むと Portable mode を使いつつ、開発中のテーマに symlink 張って開いてサンプルコードを開くスクリプトを書いてもらえた これは自分で作るとちょっと面倒くさかっただろうなと思う、これを実行してウィンドウ分割してコード並べてスクショ撮るのが俺の仕事 pokutuna/vscode-gnome2like-theme@main - resources/samples/setup_screenshot.sh AIエディタCursor完全ガイド ―やりたいことを伝えるだけでできる新世代プログラミング― 作者:木下雄一朗 オーム社 Amazon Cursor完全入門 エンジニア&Webクリエイターの生産性がアップするAIコードエディターの操り方 作者:リブロワークス インプレス Amazon
ぽ靴な缶
わんぱくな JSON ストリームパーサーを見る日
LLMこの記事は はてなエンジニアアドベントカレンダー 2024 5 日目の記事です。 昨日は id:susisu さんの Data types à la carte in TypeScript でした。 本人が「アクセス増えたと思ったら別の記事で、全然読まれてない...」と言っていたので「いきなりフランス語で難しそうやからね」と伝えました。本文は日本語なので、みなさんも読んで下さい。 今日は最近見て面白かったコードの紹介です。 ChatGPT が流行って以来、アプリでストリームのレスポンスをよく見るようになりました。 LLM によるテキスト生成はわりと時間がかかる処理で、もしすべて生成し終えてからレスポンスするとユーザーを待たせてしまうからでしょう。テキストがちょっとずつ表示される UI は昔からあるものですが、LLM を使ったアプリケーションが出てきて以来、演出としてではなく実用としてよく見られるようになったと思います。 各社が提供している LLM の API を利用する場合も、大抵ストリームでレスポンスを受け取る方法も提供されています。また自然文の生成だけでなく、指定したスキーマを埋めて JSON で構造化されたデータを返してくれる機能があります。アプリケーションに組み込みやすくて重宝しますね。 では LangChain で JSON のレスポンスストリームを読んでいる様子を見てください これは Gemini API のレスポンスを JsonOutputParser に渡していて、チャンクを受信するたびにパース結果を出力しています。 JsonOutputParser え!?!? 今みた!?!? もっとわかりやすく1文字ずつバッファに書き込んでいってパースさせてみましょう。 1文字ずつ おわかりいただけだろうか... まだリテラルが終わっていない段階でパースされた値が得られているのを... stream: {"name": "p parsed: {"name": "p"} ↑ この段階で name の値が p としてパースされてる!! stream: {"name": "pokutuna", "age": 1 parsed: {"name": "pokutuna", "age": 1} ↑ age: 1 の瞬間がある!! stream: { ... "food": ["tonka parsed: { ... "food": ["tonka"]} ↑ まだ Array 閉じてないのに!! JSON ストリームの読み込みは、いろいろなライブラリで実装されています。 例えば、NDJSON に対して行ごとにオブジェクトを受け取れるものや、JSON Path で値をひっかけるもの、SAX-like な特定のトークンが来たらコールバックを受け取るもの (もう SAX という響きが懐かしいぞ)など。 でも LangChain のこのパターンを見るのは始めてで、なにそれ!? と思ってコードを見に行きました。 この動作はこの parse_partial_json で実装されています。 github.com 文字列の開始のダブルクオートや、Object や Array の開きカッコなど、開始トークンが来るたびに、対応する閉じトークンを積んでいって、最後に reverse してくっつけて補完して json.loads しています。なかなか勢いのある実装。 内容を正確にパースをするという観点からは許されるか怪しい、レスポンスを途中までしか受け取ってないからといって、お小遣い3円の瞬間があっていいのか? しかし { "message": "長いテキスト長いテキスト長いテキスト長いテキスト... のような文字列の終わりを待ってずっと値を使えないなら、レスポンスをストリームすることで本来得たいユーザを待たせない体験が得られません。 実装も富豪的で、全体のパースを試して失敗したら1文字ずつ読んでカッコ等を積んでいく、ダメなら末尾を捨てていって試す、と何回 json.loads するつもりなのか。 これは JsonOutputParser 全体で、自然文中に JSON が含まれるレスポンス はい、指示に従って JSON で回答します。 ```json {"hoge": "fuga", ... みたいな出力もパースできるようにするためですね。 大抵「ストリームで JSON を処理したい」というと、超巨大なログを扱うとか、一度にメモリに読み込みたくないとか、実行時のリソースに意識があります。しかし LangChain のこの実装はユーザを待たせないため、途中でもいいから値を返す、Object や Array だけでなく、文字列や数値すら途中で返してしまう、AI との会話文ストリームからも取り出す、というのが面白いですね。そんなちょっとした観光名所でした。 途中の stream.py はこれ stream.py · GitHub この記事は はてなエンジニアアドベントカレンダー 2024 5 日目の記事です。 id:miki_bene さんです!! { entries.forEach(entry => { if (entry.isIntersecting) { typeText(); } else { clearTimeout(animationId); } }); }); observer.observe(element);
ぽ靴な缶
はてなエンジニアセミナーで生成 AI を利用したクラスタリングの話をしました
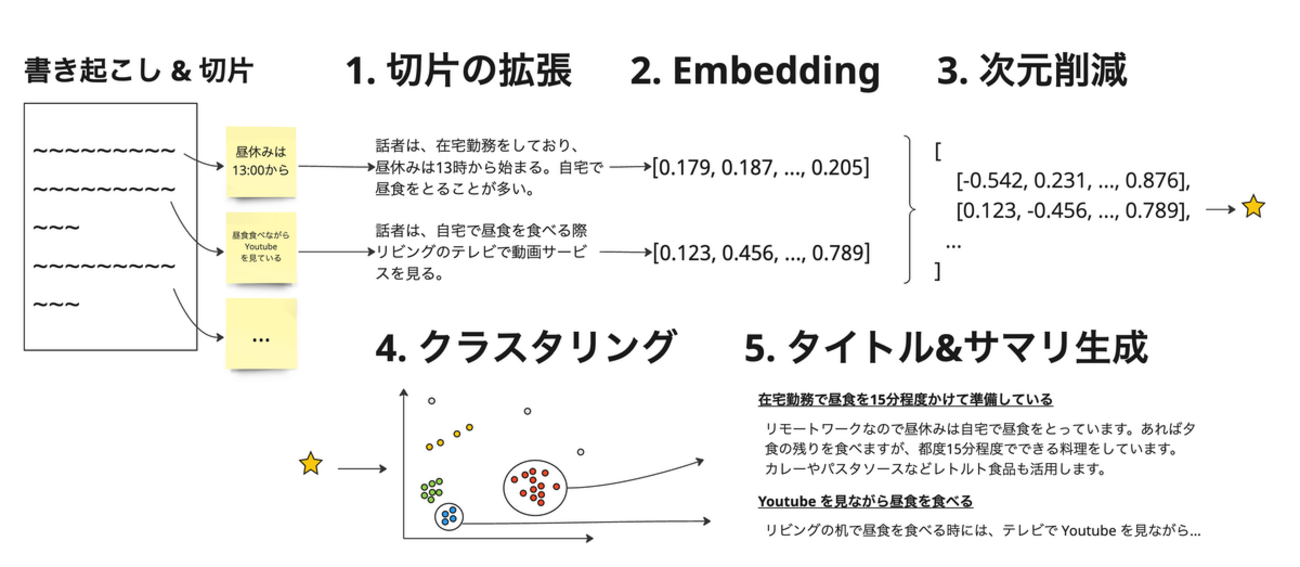
LLM発表はてな 生成AI×新規事業 の挑戦 〜生成AIを学びながら技術とチームを磨いた事業立ち上げの道のり〜 - connpass speakerdeck.com 何の因果か新規事業立ち上げ & AI 担当みたいな仕事をしております。 話題で分類するとなるとトピックモデルか? と思うけど、Vertex AI の Embedding API に task_type="CLUSTERING" を見つけ、クラスタリングでそこそこのものが出たのでそれで行くことに。改善の余地は様々ありますがとにかく HDBSCAN の性質に助けられた機能だったなと思います。 密度ベースのクラスタリング 異なる密度レベルのクラスタ得られる クラスタ形状の変化に柔軟 階層構造得られる ハイパラ調整がほぼ要らない 都合が良すぎる。 メイン図 手法の図
ぽ靴な缶
Apple Watch を買って半年
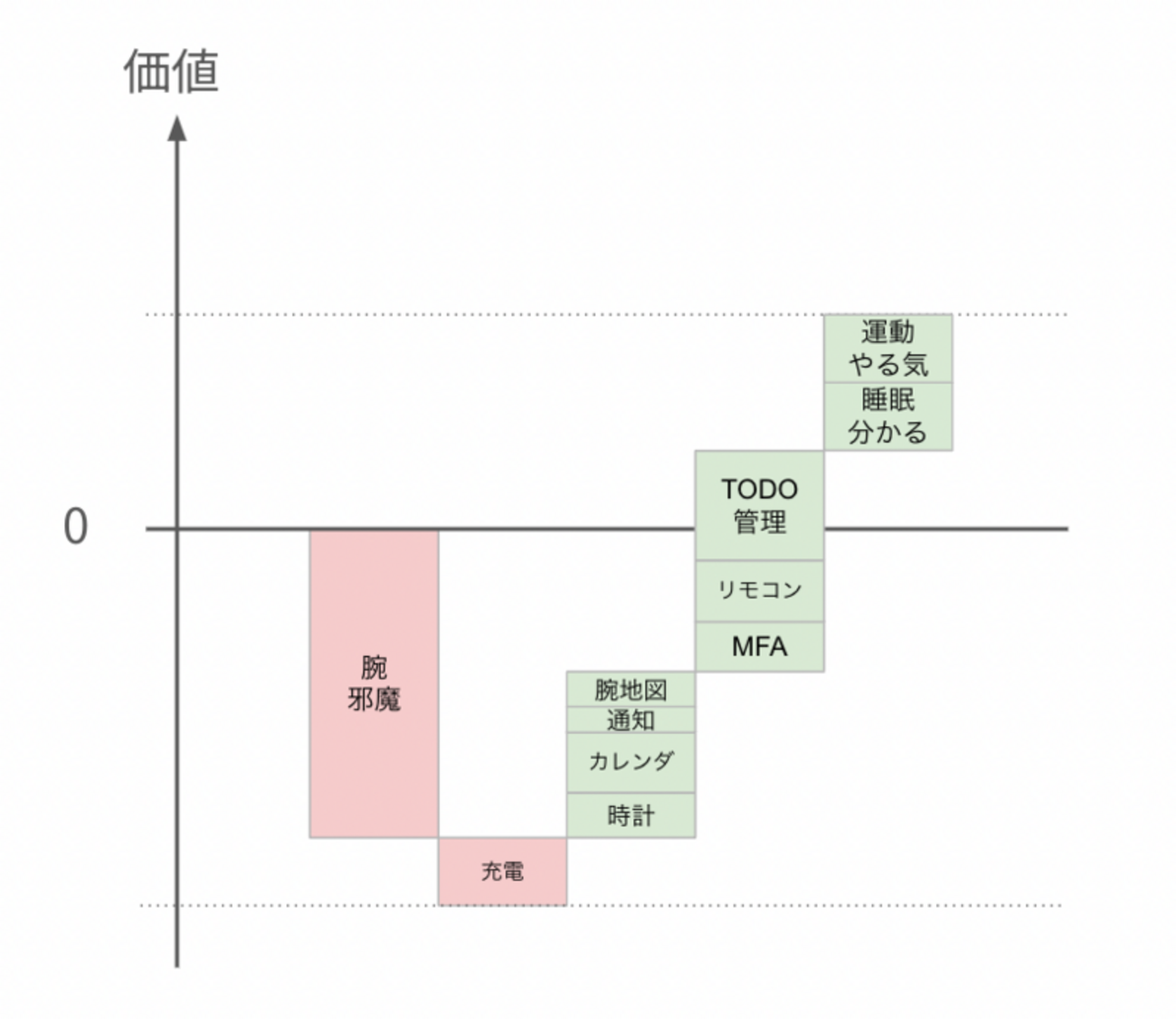
日記生活ガジェット去年の9月末に買いました。 Series 9 41mm シルバー GPS 発表を見るたびに欲しいなと思うものの、冷静に考えると要らないよな、という結論に行き着くので買ってなかった。常にスマホ持ってるでしょ。欲しい → 要らん → 欲しい というのを年1でやりつつ、ついに買ってしまった。 買ってからは便利で、風呂と充電以外は常に着けている。 生活をシャキッとさせたい フルリモートなので家から出る頻度が減って、体力も落ちだんだん太ってきた。運動習慣を付けたいけど、無策では続けられないので記録を付けるおもちゃが欲しい。他にも睡眠や心拍など Watch で体をモニタリングして遊びたい。自転車に乗っていた頃は記録に楽しさがあった。サイコンつけるし心拍計も胸に巻いてた。変化が分かると成長が見えるし満足できる。 TODO リストをもっと生活に密着させる狙いもある。Things を愛用していたけど、ここ何年も活用できてなかった。今は仕事のタスクは仕事で管理するし、生活系は記憶に頼ってもなんとかなる。なんとかなるけど、サプリ飲むとか本読むとか買い物とか、それなりに忘れているので確実に遂行しつつ習慣を作りたい。 バンド選び 買う前にずっと迷っていたのはバンド。 結局バンドはデフォルトのスポーツバンドにした。シリコン的なプニャっとしたやつ。 スポーツバンド スポーツバンド Apple Watchのバンドを購入 - Apple(日本) Watch を持ってる同僚の話を聞いて、 ブレイデッドソロループ > スポーツループ > スポーツバンド ぐらいの感じで、実物見て決めようと思っていた。しかし欲しさが最高潮の加速を使ってヨドバシで買ったので選ぶ余地が スポーツバンド or スポーツループ しかなかった。個別にバンドを選べるのは Apple Store か通販だけである。 ソロループ系は伸びるのを想定してサイズチャートより1サイズや2サイズ下が良いという真偽不明情報に惑わされて踏み切れないし、スポーツループの実物は思ったよりペラペラで、軽くて柔らかいのは分かるけど、タイトめに締めないと Watch の重さに対して慣性やズレが不快そうだなと見送った。 結果的にスポーツバンドで満足している。 4 運動などタイトにしたいとき 5 普段使い 6 洗い物したり干渉するとき むしろ締め付けず使い分けれるのが良い。通気性はないので汗をかくと多少気になるけど、そのまま時計ごとじゃぶじゃぶ洗える。冬場は手袋やパーカーの袖口のリブなんかが干渉するのでやや鬱陶しい。 腕 使ってみて いろんなものが腕で済む 時間が分かって便利、とよく言うけど、たしかに常に時計とカレンダーが腕にあるのは素朴な便利さがある。 常に次の予定がぱっと見れる。特に出社した時など、ミーティングあるのは分かっているけど会議室どこやねん、と調べるのに何かを開かなくて良い。 MFA も腕で見れる。トークン入力画面が出るやいなや端末探したり席を立つ必要がないのが良い。MFA には Authy を使っていて iPhone アプリ側のがそのまま見れる。パスワード自体も 1Password から選択的に Watch へ送っておくことができる。 腕から Nature Remo により家電が操作できる。常に腕に付いてるので、布団の中で携帯探さなくて良い。 ズボラな用途だと、布団に入ったけど、何かが PC のスリープを止めているな...まぶしい...って時に時計から pmset sleepnow している。Shortcut.app で ssh するショートカットを用意しておくとよい。 地図が腕にあるのも悪くない。 スマホ出してロック解除して地図見て、という動作をかなり頻繁にやっていることに気づく。今まで Apple Map を使っていなかったけど、Watch との連携の良さから使うようになった。Google Map の Watch アプリは地図は出ないが、スマホ側で検索したルート(主に乗り換え)を Watch で見れるので使い分けている。カレンダーの予定に場所を入れる機能も Watch でルートをシュッと表示できるので入れると便利。 母艦との連携 iPhone・Mac とのシームレスな連携がすごい。 iPhone 側のアラームは Watch も鳴って、Watch 側で止めれる、iPhone 操作している時に鳴った場合は時計は鳴らない、とかも大変良いです。外やマスク付けている時は Watch が FaceID より速く反応してロック解除できるのも良い。Mac のロックも解除できる。 通知も同期している。 iPhone にバンバン来る通知に対し、一覧を眺めて読み飛ばす運用をしていた。でもそのノリで時計で受けるのは鬱陶しすぎた。 最終的に id:cockscomb に教えてもらった時間指定要約を使って、いらねと思ったものを要約送りにしていくと必要なものだけ Watch に届くようになるし、iPhone 側は雑に受けつつ興味あるやつだけざっと見る運用ができた。 ただ iPhone 側の時間指定要約は、おしゃれなレイアウトで表示されるので、エッチな画像のレコメンドや YouTube のサムネがロックスクリーンに表示されうる。ロック中は通知を出さないようにしているが、携帯と一瞬目が合うと解除される。たまに気まずい。 Watch を買うと通知を整理する動機が生まれるし、Watch ユーザのほうが世のアプリのエンゲージメントが下がっているみたいなことが起きているんじゃないか。LINE の企業アカウントの通知とかも止めまくったし。 端末を超えて集中・睡眠モードが同期して動くのも良い。 あとここ数年ぐらいの iOS のアップデートの意図みたいなのがしっくりきた。ロック画面のカスタマイズがなんでこんな感じなの...と微妙に思っていたけど Watch と体験が共通になっているし納得感はある。 あと通知の持ち上げたとき周りの挙動がいいよね。 かわいい通知 電池の持ち 自分の使い方だと、常時点灯で1日使って 40~50% ぐらい残る。100% から 40 時間ぐらい持つ。 丸2日は持たないが、充電せず寝てしまっても十分バッファがある。 カタログスペックでは 18 時間という不安になる数字だけど、かなり時計使いまくってる状態での試験やね。バッテリなんて得てしてカタログを下回る体験だけど、倍以上保つのは意外だった。 意外と持つ 充電面倒かなと思っていたけど、意外とそうでもない。 45分で 0% → 80% のようで、実際そのぐらい。風呂の時間だけで 100% になれば最高なのだが...ちょっとは待つ必要がある。 充電自体より、ケーブルの管理が面倒。出張や外泊に持っていくものが1個増える。 サードパーティのケーブルはレモン市場感が激しく、急速充電言ってるだけだったり 5W 出てないものだったりする。そしてまともなものは MFi 取っていて高い。 Apple Watch 磁気充電ケーブル(1m) Apple(アップル) Amazon Anker 3-in-1 Cube with MagSafe: マグネット式 3-in-1 ワイヤレス充電ステーション/USB急速充電器付属/ワイヤレス出力/Apple Watchホルダー付/MFi認証/iPhone15 Apple Watch対応 Anker Amazon 睡眠の記録 睡眠トラッカーの AutoSleep が良い。 睡眠には、気絶睡眠モデルを採用しており、寝ようと思って眠ることはあまりなく、いつのまにか気絶している。十分寝たら意識を取り戻す。そういう暮らしを送っています。支障がないようウィンドウを広く取っていて、夕食後(20時) ~ 愛する妻が起きる(7時)まで、任意気絶する。 そういう感じなので、自然と10時間寝て元気なこともあれば、3時間しか寝てないこともある。記録が残っていれば眠かったり疲れてたりするのが睡眠不足かどうか切り分けられる。仕事の忙しさやストレスが睡眠に反映されているのも読み取れたりする。 夕食後に寝てない時期 気絶睡眠法の欠点として寝る前の準備というものができない。昔から Sleep Sycle を使っていたけど、iPhone に充電ケーブルを挿しつつアプリを起動して枕元に置く作業は難しすぎる。いびきを録音して聞けたりは大変楽しいのだが、意図して入眠する日だけ使える状態だった。 Apple Watch を使った睡眠記録には AutoSleep が良くて、いつ寝ても睡眠検出して記録してくれるし、起きたタイミングも勝手に残る。判定が間違ってると思うことはそんなにない。 特に「人間が寝るのは1日1回である」という非現実的な仮定を置いてないのがいい。複数回寝れるし記録が残る。 晩飯食べたあと床で30分気絶して、ベッドに這って移動してまた寝るとか、昼休みに30分寝るとか、朝飯食べたあとに二度寝するとか、現実には1日に何回も寝る。1回なわけねーだろ。 現実の睡眠活動 アプリの作りも、常にセンシングして頑張っている感じでなくヘルスケアのデータを複数突き合わせて活用している感じなのも好ましい。母機の iPhone いじってたらそれは起きてる時間だよね、とか。 リングやゲージの UI は特に分かりやすくはないです。 入力 意外とキーボード入力できる。 込み入った返事はやる気起きないが、ack 程度の内容や、TODO を 1 行だけ入力など時など普通に時計でやっている。音声入力も割と使う。 意外と入力できるキーボード Series 9 なら使えるダブルタップは良いけどタイト目につけていないと反応がわるい。今のところ通知閉じるのと、料理中に手が汚れたままタイマー止めるのが主な用途である。 アクセシビリティの Assistive Touch を使うと、色々ジェスチャで操作できてなかなかすごい体験。一度やったほうがいい。それなりには大変だけど片腕でも一通りの操作ができる。手を2回握りしめる、とかにアクションが割り当てられている。 Apple Watch で AssistiveTouch を使う - Apple サポート (日本) ダブルタップはプライマリのボタン1個押す程度のアクションしかできないので、普段もクレンチ(手を握りしめる)でセカンダリの動作ができるようになってほしいな。 運動 買ってから週に 2 ~ 3 回運動していて、意外と続いている。近所の坂の上の神社まで行って帰ってくる、約 40 分。 これ読んでインターバル速歩をやっている。 ウォーキングの科学 10歳若返る、本当に効果的な歩き方 (ブルーバックス) 作者:能勢 博 講談社 Amazon 要は (ワーク:心拍ゾーン2以上を3分 → レスト:心拍ゾーン1を3分) * 5 をやれという話だけど、運動生理学の話がおもしろい。mol から消費酸素の体積計算したりした。知らない分野の教科書みたいな読後感。 世にアプリも色々出ているが、Apple のフィットネスで独自のワークアウトを作れて、心拍ゾーン外れたら通知したりできる。これ Apple Watch からしか編集できないようで、チマチマした作業が発生して面白い。 時計でワークアウトを編集する 作ったワークアウトは共有もできる。iOS で開くと Watch に追加できる。 https://storage.googleapis.com/pokutuna-public/interval-walking.workout 本で紹介されている運動は老人向けで、だんだんと心肺機能がマシになってきたのもあり、平地の早歩きでは心拍が上がらないので、普通に走り始めた。傾斜がきついところは歩いている。するとゾーン5も使う羽目になる。 それにしても VO2max が低すぎる、35 て。 痩せにくいと思っていたけどショボすぎないか、45 ぐらいには持っていきたい。一方心拍回復は 30 まで戻ってきた。 Watch アプリのつくり アプリが全体的に割り切った作りものが多い。 Apple Map のルート検索の出発地点は現在地からのみ。出発地点や経由地を設定したければ iPhone からしろという割り切りは良いのだが、電車3路線アクセス可能な立地に住んでおり、なかなか狙ったルートで検索できないので時計から電車の時間調べるのは諦めてる。 アラームやリマインダーなど、リストに追加する系 UI の追加ボタンが一番下にありがちなのもツラい。「ヘイシリ n 分後に起こして」という指示を日々やっているので、アラームのリストはスクロールが苦痛なほど長くなっている。時計でも右上に "+" ボタン置いてくれよ。 ピークタイム スマホ経由で通信する都合上、ネットワークエラーやタイムアウトに出くわしやすい気がする。やたらローディングのままだったり、タイムアウトした時にアプリをキルしないと何もできなかったり。 微妙なアプリの作りの悪さもありがち。 Watch の Siri のサジェスト押した時の動作定義してないのか、最低限アプリが起動すればいいのだが謎のウィンドウが開いてくるくるするだけとか。 母機の iPhone を経由する遅延やリトライがそこそこある上に、状態を iPhone 側に保存していたら通信して読まないといけないだろうし、考えることが多く画面も小さくフィードバックも難しそうではある、その上ユーザは限られてるとなると力も入らない気持ちは分かる。 価値 収支 図にするとこんな感じ。 腕に時計を着け続けるのは明らかに邪魔なのだが、様々な便利さにより総合的には良い。 追記 あたりまえすぎてタッチ決済に言及していなかった。 まじめにやってくれ天気.app
ぽ靴な缶
OSS 観光名所を貼るスレ
OSS活動インターネットこれは はてなエンジニアアドベントカレンダー2023 2日目の記事です。 はてなエンジニア Advent Calendar 2023 - Hatena Developer Blog はてなエンジニアのカレンダー | Advent Calendar 2023 - Qiita トップバッターは緊張するけど、順番が回ってくるまで長い間ソワソワするのも嫌、という理由で例年2日目を狙うようにしている id:pokutuna です。今年も成功しました。 観光名所とは 目を閉じれば思い出す、あのコード... あの Issue... あなたが Web 系のエンジニアであれ、趣味で開発している方であれ、必要に応じてライブラリやフレームワークのコードを読むのはよくあることでしょう。公開の場で開発されているソフトウェアは、ソースコードだけでなく、開発コミュニティでの議論やバグ報告なども見ることができます。 リポジトリを覗き見していると、思いもよらない実装や、記憶に残るディスカッション、バグレポートまでいろいろな営みが見つかります。 私はそういったものを「観光名所」と呼んでコレクションしています。 今日はよく知られているソフトウェアの GitHub 上にある観光名所をピックアップして紹介します。 観光名所たち __SECRET_INTERNALS_DO_NOT_USE_OR_YOU_WILL_BE_FIRED (facebook/react) facebook/react@60ad369 - packages/react/src/React.js#L128 export { ... ReactSharedInternals as __SECRET_INTERNALS_DO_NOT_USE_OR_YOU_WILL_BE_FIRED, これはちょっと有名かも、ReactSharedInternals が export される際の物騒な名前。React の内部状態が入っています。 まあ必要があって export しているわけで、テストや react-dom など他の packages/ 以下からちょいちょい参照されている。package として公開しているが、これに依存した機能なんて作るなよというメッセージが明確に表現されています。まあドキュメントやコメントで言っても読まれませんからね。 Node.js の HTTP ヘッダの小文字化 (nodejs/node) nodejs/node@60ffa9f - lib/_http_incoming.js#L279 function matchKnownFields(field, lowercased) { switch (field.length) { case 3: if (field === 'Age' || field === 'age') return 'age'; break; case 4: if (field === 'Host' || field === 'host') return 'host'; if (field === 'From' || field === 'from') return 'from'; if (field === 'ETag' || field === 'etag') return 'etag'; if (field === 'Date' || field === 'date') return '\u0000date'; if (field === 'Vary' || field === 'vary') return '\u0000vary'; break; case 6: if (field === 'Server' || field === 'server') return 'server'; if (field === 'Cookie' || field === 'cookie') return '\u0002cookie'; if (field === 'Origin' || field === 'origin') return '\u0000origin'; if (field === 'Expect' || field === 'expect') return '\u0000expect'; if (field === 'Accept' || field === 'accept') return '\u0000accept'; break; case 7: if (field === 'Referer' || field === 'referer') return 'referer'; if (field === 'Expires' || field === 'expires') return 'expires'; ... Node で HTTP ヘッダを扱う際、ヘッダ名を小文字で扱っていることに気づきます。RFC2616 → RFC7230 → RFC9112 の歴史ある仕様にあるように、ヘッダ名は大文字小文字を区別しないので、すべて小文字に寄せているようですね。 何度も実行されるところなので、パフォーマンス優先のためになかなか激しい実装になっています。toLowerCase を呼ぶ回数を減らすため、一般的なヘッダはハードコードされており、文字列比較の回数を減らすため前段で文字列長で分岐しています。 返す文字列の1文字目がフラグになっている、というのもなかなかです。同じヘッダが複数回出現する場合の区切り文字や、Cookie & Set-Cookie の扱いを制御しています。 VSCode のコマンドがローカライズされる (microsoft/vscode) Don't localize command names on the command palette · Issue #4679 · microsoft/vscode VSCode の開発版である Insiders Build にリリースされた変更。 コマンド名が翻訳されて、git pull ではなく git プル と入力する必要がでてくる。やめてくれという意見で CJK 圏の気持ちが一つになった事件。 Issue を立てるだけでなく、繰り返し問題を説明する @espresso3389 さんの活躍が光る Issue です。これが安定版に降ってこなくて本当に良かったですね。ソフトウェアをローカライズする際の難しさも垣間見えます。 A picture of a cute animal (moby/moby ほか) moby/moby@75546e1 - .github/PULL_REQUEST_TEMPLATE.md Please provide the following information: ... **- A picture of a cute animal (not mandatory but encouraged)** moby は、以前モノリシックな構造だった Docker リポジトリをコンポーネント化していったもので以前は docker/docker でした。今も Docker の実装に使われています。その moby の Pull Request テンプレートには、かわいい動物の画像を貼るコーナーがあります。 例 https://github.com/docker/compose/pull/11213 (moby じゃなかった) https://github.com/moby/moby/pull/32061 (アスキーアート) https://github.com/moby/moby/pull/27455 (どういう状況?) https://github.com/moby/moby/pull/34895 (🐼で済ませる) でも最近の Pull Requests を見るに、そんなに貼られてはいなさそう。 その他 docker 関連リポジトリにおいても動物画像コーナーがしばしば見られます。 docker/compose@c582470 - .github/PULL_REQUEST_TEMPLATE.md docker/cli@c1455b6 - .github/PULL_REQUEST_TEMPLATE.md Steve Wozniak is not boring (moby/moby) moby/moby@75546e1 - pkg/namesgenerator/names-generator.go#L852 if name == "boring_wozniak" /* Steve Wozniak is not boring */ { goto begin } こちらも moby から、Docker コンテナの自動命名にある唯一の例外。 docker run でコンテナを起動した際、ランダムな名前が割り当てられるのはこの names-generator.go の実装によるものです。"形容詞" と "科学者やハッカーの名前" の2つのテーブルから選んで結合したものになる。 形容詞のテーブルに boring、人名のテーブルに wozniak が含まれていますが、boring_wozniak という名前がコンテナに割り当てられることだけはありません。なぜなら Apple 創業者の Steve Wozniak は退屈ではないので。 goto で戻ってやり直しているのも普段あまり見ないので面白いですね。 そういえば Elasticsearch の node 名は Marvel キャラクターから選ばれるんだっけ、と見に行ったら 5.0 からなくなっていた。めっちゃ前じゃん elastic/elasticsearch@v2.4.6 - core/src/main/resources/config/names.txt Trick and AttributeError 事件 (pypa/pipenv) Halloween easter egg breaks · Issue #786 · pypa/pipenv pipenv は Python のインタプリタと依存ライブラリのバージョンを管理する bundler ツール。 普段のプログレスバーは 🐍 の絵文字で表示されるところ、ハロウィンだけ 🎃 になるというイースターエッグが仕込まれていました。しかしそこにバグがあり、ハロウィンだけ例外が出て依存をインストールできなくなる事態に。 ちょうどこれでデプロイ不能になってハマったのでよく覚えている。ここがいきなり壊れると思わないだろ。 累計100万DLを突破したダイエットアプリ(無料)の『もぐたん』! (google/zetasql) google/zetasql@589026c - zetasql/compliance/testdata/strings.test#L911 -- ARRAY<STRUCT< STRING, formatted_description STRING >> [ { "累計100万DLを突破したダイエットアプリ(無料)の『もぐたん』!\nおかげさまで、ヘルスケア/フィットネス 無料カテゴリで1位獲得!\n\n◆かんたんスタンプ入力 \n文字で書かなくても食べ物スタンプで簡単に記録出来ちゃう!\n\n◆『もぐたん』がみんなを応援\n入力する度にもぐたんがゆるくて可愛いコメントをくれるよ!\n毎日体重を入力して『もぐたん』の「きせかえ」をGETしよう!\n\n◆ダイエットの成果はグラフでチェック\n体重を入力するとグラフに反映されるから変化がまるわかり!\n摂取カロリーの推移もグラフでチェック出来ちゃう!\n\n◆体重と一緒に運動スタンプを入力\n運動もスタンプでかんたん入力!\n毎日どのくらいダイエットしたかがひと目でわかるよ!\n\n◆ 自動カロリー計算機能\nプロフィールを入力すると、あなたに合った摂取カロリーの目安がわかるよ!\n\nhttps://itunes.apple.com/jp/app/daietto-ji-lumogutan-ke-aiisutanpude/id882365789", '"累計100万DLを突破したダイエットアプリ(無料)の『もぐたん』!\\nおかげさまで、ヘルスケア/フィットネス 無料カテゴリで1位獲得!\\n\\n◆かんたんスタンプ入力 \\n文字で書かなくても食べ物スタンプで簡単に記録出来ちゃう!\\n\\n◆『もぐたん』がみんなを応援\\n入力する度にもぐたんがゆるくて可愛いコメントをくれるよ!\\n毎日体重を入力して『もぐたん』の「きせかえ」をGETしよう!\\n\\n◆ダイエットの成果はグラフでチェック\\n体重を入力するとグラフに反映されるから変化がまるわかり!\\n摂取カロリーの推移もグラフでチェック出来ちゃう!\\n\\n◆体重と一緒に運動スタンプを入力\\n運動もスタンプでかんたん入力!\\n毎日どのくらいダイエットしたかがひと目でわかるよ!\\n\\n◆ 自動カロリー計算機能\\nプロフィールを入力すると、あなたに合った摂取カロリーの目安がわかるよ!\\n\\nhttps://itunes.apple.com/jp/app/daietto-ji-lumogutan-ke-aiisutanpude/id882365789"' } ] zetasql は BigQuery や Cloud Spanner 内で利用されている Google の SQL Parser & Analyzer です。 その utf8 文字列のテストデータとして「もぐたん」という iOSアプリの App Store 説明文らしきものが使われています。そこは Play Store じゃないんかい。 zetasql は、BigQuery 大好きパーソンが中を知りたい時に当たれる数少ない公開コンポーネントです。謎に満ちており、OSS ではあるもののコミュニティ主導ではなく ZetaSQL Team ユーザが数週間に1回変更をまとめて push する、人の侵入を望まない霊峰のような風情。 もぐたんは現在サービス終了していますが、かわいいクマチャンが出てくるアプリです。zetasql との温度差で交互浴の気分になります。 ダイエット・カロリー・体重記録アプリもぐたん(applion より引用) 参考 Google の SQL parser/analyzer の ZetaSQL とは何であるか | by apstndb | google-cloud-jp | Medium 公開論文から学ぶ Google のテクノロジー : パート 3:データベース技術編 | Google Cloud 公式ブログ Promise.race で DNS & IP 両方にリクエストを投げる (googleapis/gcp-metadata) googleapis/gcp-metadata@27f0a12 - src/index.ts#L186-L187 let responded = false; const r1: Promise<GaxiosResponse> = request<T>(options) .then(res => { // ... }) const r2: Promise<GaxiosResponse> = request<T>(secondaryOptions) .then(res => { // ... }); return Promise.race([r1, r2]); これは Google Cloud のメタデータサーバーにリクエストする実装です。 メタデータサーバーは GCP 内のネットワーク内から到達でき、実行環境に応じた情報取得や認証を行うため、ほとんどのクライアントライブラリが内部的に叩いています。 ここではメタデータサーバーの metadata.google.internal. と、それを解決したリンクローカルアドレスの 169.254.169.254 に並行にリクエストを投げて先に成功した方を使うという実装になっています。 そんなことしていいの、と驚くけど、GCP 内の名前解決が遅い環境では 169.254.169.254 が先に結果を返すでしょうし、GCP 外のユーザのローカル環境などでタイムアウト待ちになったとしても metadata.google.internal. が解決できないので名前解決程度の短時間で失敗できる、という感じでしょうか。合理的ではあります。こんなコアっぽいところでリクエストを倍にしちゃうんだ。 関連: GCP の Application Default Credentials を使った認証 - ぽ靴な缶 命名に関する議論 命名に関する議論は紛糾しがちです。 GitHub は 2020 年 10 月にデフォルトブランチ名を master から main に変更しました。日本語圏だけでもいろいろな意見が飛び交いましたね。 The default branch for newly-created repositories is now main - The GitHub Blog 先程の Docker コンテナ命名の実装についても、議論の末に変更を凍結する判断がされています。 Freeze the namesgenerator package against new additions by tianon · Pull Request #43210 · moby/moby このコメントの一部を機械翻訳し、調整したものを引用します 私たちはこの変更についてメンテナ会議で議論し、私たち全員がこのパッケージの最初の アイデアを気に入っていたにもかかわらず、何年もかけてこのパッケージは 望ましい以上のメンテナンスが必要になり始めたという結論に達しました。 いくつかの例を挙げますと、何年もの間、名前の組み合わせが不幸な組み合わせになったり、形容詞がすべての状況に適していなかったり、否定的な意味を持つようになったり、リストの人々が物議を醸すようになったりしたため、私たちはリストの変更を余儀なくされてきました。さらに、技術的な制限(姓が一意でないこと、名前の長さ、名前がアスキーに限定されているため、暗黙のうちに多くの地域の名前が除外されていること)もあり、事態を複雑にしています。 リンクされているコミットでは、形容詞の cocky は人に付けるのは適切でなかったり、kickass, insane など俗語的にはポジティブな意味(ヤバすぎ、のような)でも、フォーマルな文脈では厳しいので消したり置き換えられたりしています。 この "物議" が指すのは、エプスタイン事件において疑惑のある Marvin Minsky や、それへの言及が問題となった Richard Matthew Stallman についての話で、人名テーブルから除く変更が行われています。 リチャード・ストールマン氏、MITの役職とFSF総裁を辞任 エプスタイン関連コメントへの批判で - ITmedia NEWS かつてはおもしろ機能だったものが、社会的な価値観の変化やより広い人々を包摂するにつれて、不適切とみなされるようになっていく、ということが起きています。 他に命名に関する議論で思い出されるのは、FactoryGirl や Tsunami でしょうか。観光名所というと面白がっているニュアンスで聞こえるかもしれませんが、fun ではなく controversial な、記憶に残るものとして紹介します。 FactoryGirl が FactoryBot に変更 (thoughtbot/factory_bot) Repository Name · Issue #921 · thoughtbot/factory_bot こちらは Ruby のテストデータのファクトリライブラリである FactoryGirl が、FactoryBot にリネームした際の議論。 FactoryGirl は、Factory パターンと Rolling Stones の曲に由来する名前ですが、「名前の由来はなんなの?」という質問に端を発し、女性差別的ではないか、男性多数なソフトウェア業界のバイアスがあるのではないか、という議論から FactoryBot にリネームされました。 リネーム反対意見に同意する emoji の数や、女性による変えなくて良いというコメントが繰り返し言及される中(「当の女性が問題にしていないじゃないか」的な)、冷静にリネームの判断を下していてすごいですね。6 年前の話ですが、今やると emoji の傾向も大分変わるんじゃないでしょうか。不快だと思っていてもこの荒れた Issue では表明するのも難しいでしょう。 一方 FactoryGirl の Python 版といえる FactoryBoy はそのまま行くという判断をしています。 factory_girl --> factory_bot by alexgleason · Pull Request #442 · FactoryBoy/factory_boy Consider renaming to FactoryPy or the like · Issue #912 · FactoryBoy/factory_boy · GitHub Tsunami の命名に関する議論 (google/tsunami-security-scanner) I'm not sure if "Tsunami" is a good name. But I need your opinion. · Issue #5 · google/tsunami-security-scanner 津波のような攻撃から身を守るセキュリティスキャナーという命名ですが、Tsunami って命名はどうなの? 東日本大震災の津波を思い出す人もいるんじゃない? という Issue です。master/slave や whitelist/blacklist は、どこか外の話のように感じる人も多いと思いますが、これは日本人が当事者になったトピック。 当時はてなブックマークでも話題になっていました。 Googleのセキュリティスキャナー「Tsunami」、名称がGitHubで議論呼ぶ 関係者が参加し釈明 - ITmedia NEWS 性別の話に比べ、かなり抑制的に議論が行われていると思います。津波という名前だから破壊する方のツールかと思った、という尤もな指摘もあります。 ...それはそれとして、この議論の数ヶ月後に、google/tsunami が push されています。TSUNAMI (TypeScript Untar Multiple Reads) の略だそうです。偶然でしょうが、変なオチがついた気持ちになりました。 XML は暴力ではない (sparklemotion/nokogiri) Removing reference to violence. · sparklemotion/nokogiri@ddd8e1d - XML is like violence - if it doesn’t solve your problems, you are not - using enough of it. - ポリティカルコレクトネス的な変更で思い出すのは Nokogiri です。Ruby の XML パーサーですが、README から以下の行が暴力を賛美しているということで削除されました。 XML is like violence - if it doesn’t solve your problems, you are not using enough of it. XML は暴力のようなもので、それで問題が解決しないのであれば、使い方が足りないのだ。) まあ明らかにジョークだし、このぐらいいいんじゃないの...と思うものの、暴力に怯える状況で XML をパースする際には複雑な気持ちになるかもしれません。 自分がどの立場になるか、という問題は常にあります。 Facebook にクビになった人は、React の __SECRET_INTERNALS_DO_NOT_USE_OR_YOU_WILL_BE_FIRED を面白がれるでしょうか。いやしかし、他者の痛みを想像しつつも、勝手な想像で他人の喧嘩をしないほうがいい、というのが私の気持ちです。 もはや GitHub デフォルトブランチが main なのが当たり前になり、むしろ master を見ると古臭く感じるようになりました。そんな心情の変化に時代の流れを感じますね、とここまでを締めることにする。 その他小粒なもの 特に説明しても面白さに資さないけど、記憶に残るもの 猫がキーボードの上を歩いた結果立った Redis の Issue ///33333333333333333333333333333333333333333333333333333333333333333333333333333333333333333-g=-[=. · Issue #3909 · redis/redis if enabled then "Disabled" まあ稀にこういうことをする羽目に陥る hashicorp/terraform-provider-azurerm@v2.67.0 - azurerm/internal/services/network/subnet_resource.go#L524-L533 Google Analytics の dimesion1 ~ dimension200 までの型定義、metrics1 ~ metrics200 もある DefinitelyTyped/DefinitelyTyped@ad1ea50 - types/google.analytics/index.d.ts#L84-L283 OSS 以外 タイトルの引き欲しさに OSS と書いたので、ここまでオープンソースライセンスと言えるものを挙げてきました。それ以外で記憶に残っているものをちょっと紹介します。 "You are not expected to understand this" (Version 6 Unix) 超有名な一節。コードが分かる人に比して圧倒的にコメントが流行っている。僕もわかりません。 BSD で配布されているようですが原典的にはこの枠で。 2230 /* 2231 * If the new process paused because it was 2232 * swapped out, set the stack level to the last call 3333 * to savu(u_ssav). This means that the return 2235 * actually returns from the last routine which did 2236 * the savu. 2237 * 2238 * You are not expected to understand this. 2239 */ 2240 if(rp->p_flag&SSWAP) { 2241 rp->p_flag =& ~SSWAP; 2242 aretu(u.u_ssav); 2243 } 解説の翻訳 あなたが見た中で最も有用なコードコメントは何ですか? - Quora SQLITE_TEMP_FILE_PREFIX "etilqs_" (mackyle/sqlite) mackyle/sqlite@18cf471 - src/os.h#L65-L79 #ifndef SQLITE_TEMP_FILE_PREFIX # define SQLITE_TEMP_FILE_PREFIX "etilqs_" #endif SQLite は軽量でファイルベースのデータベースです。著作権を放棄した Public Domain で公開されています。 身近なモバイルアプリやブラウザのローカルなデータベースとして組み込まれていたりします。Chromium の履歴やブックマークでも使われているようですね。SQLite abstraction layer そんな SQLite の一時ファイルは、sqlite を逆さに読んだ etilqs_ が prefix になっています。 理由はこちらの @EzoeRyo 氏のツイートでどうぞ。 マカーフィーがSQLiteを使っていて、C:\tempに一時ファイルを作ったため、ファイルを見て疑問に思った馬鹿なユーザーがsqliteを検索し、出てきた開発者の電話番号に「テメェ責任者かコラ、ファイル消しやがれゴルァ」という迷惑電話をかけまくったため、逆さ読みのetilqs_に変更された。 — 江添亮 (@EzoeRyou) 2023年6月13日 おわりに コレクションしていた観光名所を一通り放出しました。 みなさんの知る観光名所はどんなものがあるでしょうか? コメントやはてなブックマークコメントでぜひ教えてください!! チャンネル購読と、高評スターもお願いします。 また、労働をしていると社内の開発リポジトリに観光名所を見つけることもあります。きっと皆様の会社にもあることでしょう。 様々なしがらみで修正できずそのままになっている typo 議論が白熱しすぎてもはや喧嘩している Issue デカい障害を引き起こした名コミット 狂った命名 遺言に見えるコメント Revert を Revert した回数最高記録 いちばん長い SHA1 のゾロ目を探して遊ぶ などなど、興味がある方はこちらから入社してください。日本全国フルリモートOK!! hatena.co.jp 実用的な情報 ちなみに GitHub のソースコード表示中に y を押すと、URL が main などブランチ名から コミットID が含まれるものに変わります。こういう記事や、ドキュメントを書くときに便利ですね。ファイルへのパーマリンクを取得する - GitHub Docs また、cocopy でリンクテキストを生成するとさらに便利ですよ。 blog.pokutuna.com こんな関数で、デフォルトは Markdown、Shift キーを押している時は Scrapbox 記法でコピーしています。 ({title, url, modifier}) => { const pattern = /https?:\/\/(.+)\/(?<user>.+)\/(?<repo>.+)\/blob\/(?<rev>[^/]+)\/(?<file>[^#]+)(?<hash>#.+)?/; const g = pattern.exec(url).groups; title = `${g.user}/${g.repo}@${g.rev.substr(0,7)} - ${g.file}${g.hash || ''}` return modifier.shift ? `[${title} ${url}]` : `[${title}](${url})`; } この記事は はてなエンジニア Advent Calendar 2023 2日目の記事でした。 明日の担当は id:mechairoi さんです。楽しみですね。 blog.chairoi.me 追記 ブックマークありがとうございます。 挙げてもらった観光名所にリンクしておきます。 ちょっと小粒よりだけど Sidekiq にある❤という名前のメソッドはおもしろ命名なので観光名所としてオススメですhttps://t.co/FkHiOH6amS OSS 観光名所を貼るスレ - ぽ靴な缶 https://t.co/Js9w9VQlZI — 藤秋 (@f_subal) 2023年12月2日 「デカい障害を引き起こした名コミット」の例だとaxiosでXSSを防ぐために"on〇〇"を含むクエリパラメータを全部エラーにしたやつが思い出されるかなhttps://t.co/z20FtZkLzx — 藤秋 (@f_subal) 2023年12月2日 TypeScript が急に 3.3.3333 ってバージョンを作って怒られる回 https://t.co/nnqwJrUGBG とか、Jest が10000個目の PR で馬鹿になっちゃった回 https://t.co/KTNhPWDLQx とか好き OSS 観光名所を貼るスレ - ぽ靴な缶 https://t.co/ScIsJyGC0e — ksakahieki@恋垢 (@ksakahieki) 2023年12月2日 GitHub のRails リポジトリがハックされたやつも載せてほしい https://t.co/4KqXswesMX / “OSS 観光名所を貼るスレ - ぽ靴な缶” https://t.co/vbd1Nx698o — suginoy (@suginoy) 2023年12月2日 OSS 観光名所を貼るスレ - ぽ靴な缶 これも <a href="https://tech.a-listers.jp/2011/06/17/epic-fail-on-github/" target="_blank" rel="noopener nofollow">https://tech.a-listers.jp/2011/06/17/epic-fail-on-github/</a> 2023/12/03 00:33 OSS 観光名所を貼るスレ - ぽ靴な缶 個人的にはこれ→<a href="https://github.com/cocoa-mhlw/cocoa/issues/95" target="_blank" rel="noopener nofollow">https://github.com/cocoa-mhlw/cocoa/issues/95</a>「OSのプロキシ設定を無視したHTTP接続を行っている」 2023/12/03 01:34 おもしろかった。個人的にはUI LibraryのAnt Designで、クリスマスになると勝手にデザインが変わる時限爆弾を思い出した。https://t.co/QC92u9sa0L / “OSS 観光名所を貼るスレ - ぽ靴な缶” https://t.co/a3kEb8CzE3 — snagasawa (@snagasawa_) 2023年12月2日 弊社のリポジトリでは変数の横に*が10個付いたCのコード(ポインタのポインタの…って10回分)が発見されて話題になったことがあるhttps://t.co/PMdgMEqy3c — ぞりお (@__zorio__) 2023年12月3日 これは楽しいw/命名関係は色々意見があるよねぇ…/個人的には古いけど「membarrier()システムコール」の話が大好きw https://t.co/yBJF2NuIkL / 他39件のコメント https://t.co/1EtRLNGIF8 “OSS 観光名所を貼るスレ - ぽ靴な缶” (331 users) https://t.co/FJZlUX0fAO — wisboot (@wisboot) 2023年12月3日
ぽ靴な缶
Google Cloud 認定 Professional Data Engineer 取りました
GCPデータやったー Google Cloud の主催する Google Cloud Innovators Gym Japan (G.I.G) というプログラムに参加して取りました。 Google Cloud を利用する企業を対象とした招待制のプログラムで、参加すると関連する Coursera コースへのアクセス、試験を受けるためのサポート、Google Cloud エンジニアの方によるハンズオンや質問できる機会が提供されます。 バッジ 以下の資格が対象。今回のプログラムは4月中頃に始まり、7月中頃までに Coursera のコースを終え合格報告をするスケジュール。お話を頂いて良い機会なのでチームの若者を誘って参加しました。 Professional Cloud Architect Professional Cloud Developer Professional Data Engineer pokutuna は公式ドキュメント読んで筋の良い手段を取ればいい、正直俺ならいつでも資格は取れる... という傲慢さを持っているわけだけど、なら取れよと思うのも当然の話、無免許で Google Cloud を触っている事実は覆せない。なら GW 予定もなんもねえし最速で取ってやるわいと、GW 中に PDE コースの Coursera を終え、記憶が揮発しないよう頭皮をキュッと絞めながら5月末に試験を受けた。 普段やってる範囲については良い再確認の機会になった。各プロダクトそれぞれのドキュメントを読みつつ、過去の経験や一般的なソフトウェアに対する感覚で色々判断しているわけだけど、Coursera の授業を聞くとまあそうなるよね間違ってなかったわとなるし、微妙に知らないことや使ってない機能の知識も補えた。あと同僚に説明する時も言語化しやすくなったと思う。普段使っていない Dataflow や BigTable はフムフムと授業を聞けた一方、Dataproc はモチベーション上がらなかったな。今から Spark や Hadoop を選択しない...という気持ちがある。Data Engineer でも ML の話はあるものの概念や手法の一般的な話なのでまあいける。再現率と適合率、どっちがどっちか毎回忘れるので覚えたけど、テスト勉強自体 10 年ぶりなので懐かしい感じがした。 印象に残ったのはコンピューティングとストレージの分離の話。 アーキテクチャの話として出てくるけど、クラウドやサーバレスの切り口にもなる話だった。この 2 つを分離できるなら一気にスケールできて、ボトルネックがネットワークに移る。分離できないアーキテクチャだったら2つセットの仮想マシン的な単位で借りないといけない、1台のキャパシティに気を揉むことになる。サーバーレス以前のアプリケーションはそうなりがちだし、要求が高い OLTP な DB だったりしてもそうなる、みたいな理解ができる。 そう考えると Spanner はめちゃすごいし、その後に演習で BigTable インスタンス作るけど、操作可能になるまでの速さにびっくりするのでうまく出来ているんだなと思う。 もう1つは、秘訣(The secret sauce) - How Google does Machine Learning で出てくる "自分で見たことがないデータは準備不足" という話。気に入ったところを引用する。 十分なデータが集まってない またはアクセスできない時点で MLについて話しても無意味です 実はデータがあるかもしれませんね 何年も記録し 別の部署が管理しているシステムに あるかもしれません でも実際に見たことはありません 私は自信を持って言います 自分で見たことがないデータは準備不足です それだけでなく 定期的にそのデータを確認して レポート作成や新たな発見をする人が 組織にいないなら つまり そのデータがすでに 価値を生み出していないなら データの保守に努力が 払われていない可能性が高く データが次第に廃れていきます これまで対話したクライアントの中で クリーンデータを集める労力を 過小評価しない人には 会ったことがありません 「思ったより簡単だった」と言う人はいません 多くの苦労や障害に直面するでしょう おっしゃる通りです、感動で泣ける。 これは ML Engineer の授業なんだけど、規定の 3 コース以外の Coursera にもアクセスさせてもらえるので見れた。ありがたいですね。 試験について 公式の模擬試験は初見 88% 正答だったので、まあ見直せば合格やろと思いつつ念のため Kindle で売ってた模擬問題集をやったりした。要件に応じてどのプロダクトを選ぶかとか、コスト最適化とか定番問題は色々ある。読みながら雑にまとめたメモはこれ、メモなので整理されてはいないけど助けになる人も居るでしょう。Processional Data Engineer - pokutuna 模擬問題集には、かなりの悪文があったり、その選択肢じゃ一意に決まらなくない? と思う問題もあった。商品レビューで低評価されているものの、ある意味かなり役に立ちました。Coursera だけで試験突撃してたら落ちてた可能性ある。で、こういう問題集なんですが... 真面目に作ってる人も居そうですし、言いがかりになると悪いんだけど... これ英語の書籍や海外コミュニティの問題を機械翻訳したやつだったり、公式模擬試験を更新のたびに集めたやつだったりしない? 俺が見たヤツはそういう感じが漂っている... 役には立ったし恩は感じるけど、宣伝したくはないという複雑な気分。 試験は大阪の Kryterion と提携するテストセンターで受けた。リモートも選べたけど、専用ソフト入れたり部屋を片付けて試験官に見せたりしたくないなと。行って受付したら、即ロッカーに私物全部入れて待っててくださいという感じだったのは予想外だった。試験開始時間を待ちながら携帯で見直す想定だったんだけど...もっとギリギリに行ってもよかった。試験は席ごとに衝立が置かれた学校の PC 教室のようなところで受ける。同じ部屋の受験者同士で受けてる試験は違っていて、待っている間の周囲の会話の感じだと、TOEFL や Microsoft Office の資格試験なんかも同時にやっているようだった。 あとこれは規約で共有を禁じられた試験内容にあたらないと思って書くんですが、環境が中華フォントで問題文が読みづらかった...理解するのに支障はないけど、ボタンラベルが 見直す になってるのは日本語表示環境じゃないでしょう。 認定証の検証 試験に合格すると、Accredibleで認定証とバッジ画像が発行される。 そんで認定証の存在がブロックチェーンに記録されてるらしいじゃないですか、しかも BTC。BigQuery に精通する Professional Data Engineer として、証明書の存在を UDF で検証しつつ bigquery-public-data.crypto_bitcoin.blocks の行を SELECT する SQL を披露するのが合格エントリに相応しい。 そう思ってマークルツリーの仕組みとか読んでみたけど、肝心のリーフとなる自分の証明書の SHA256 を得る方法が分からない。このドキュメントの "similar to ~" で濁されているところが知りたいんだけど... 一応 blockchain-certificates/cert-schemaを読んで、Accredible の blockchain data API から得られる JSON 中の credential_json_data を URDNA2015 & nquads で正規化したりしてみたんだけど、API のレスポンスに含まれるハッシュにならなかった。証明書と btc_anchor_branch からこのクエリの merkle_root を計算して SELECT してドヤ、という予定だったんだけど、興味が続かなくて諦めた。 SELECT * FROM `bigquery-public-data.crypto_bitcoin.blocks` WHERE merkle_root = "de49e548fe4fb7b8b01f263b101c87f08a3c384c9d0e6d873daa179378ae5376" AND timestamp_month = "2023-05-01" Open Badge の仕様は読んでみて、バッジの png 画像から URL を取り出すのは書けた。記事冒頭のバッジ画像から取り出せるよ。 badge.go · GitHub